
Level: Medium project
GitHub Repository: https://github.com/JaumeAlbardaner/handwritten-character-segmentation
Grade: A (10 out of 10)
What is a "Character Segmenter"?
A character segmenter is an entity that is capable of discerning the union boundaries between two or more characters. When it comes to computer-generated characters, as there is a standard on what form each character is to take, the problem is trivial. However, the problem becomes incredibly complex as these characters are to be segmented from handwritten text.
Our project
For this project, two separate approaches were conducted:
- CNN For this approach, it was assumed that a character was perfectly photographed, and the only task left was to identify which one it was.
- UNet For this approach, the assumption previously introduced was removed. The algorithm had to both find the pixels relevant to each letter and classify them.
Building the dataset
In order to build a dataset, different classmates were asked to handwrite the following text:
The quick brown fox jumps over the lazy dog.
Pack my box with five dozen liquor jugs.
How vexingly quick daft zebras jump!
Sphinx of black quartz, judge my vow.
Jackdaws love my big sphinx of quartz.
The five boxing wizards jump quickly.
Waltz, bad nymph, for quick jigs vex.
Quick zephyrs blow, vexing daft Jim.
Two driven jocks help fax my big quiz.
Quick, Baz, get my woven flax jodhpurs!
This text was then preprocessed, and each of the letters that appeared in them were properly labelled to conform the final dataset.

Approaches
CNN
In order to train the CNN with the best possible hyperparameters, the Keras Tuner was applied. With the resulting configuration, the following confusion matrix was obtained on the validation data:
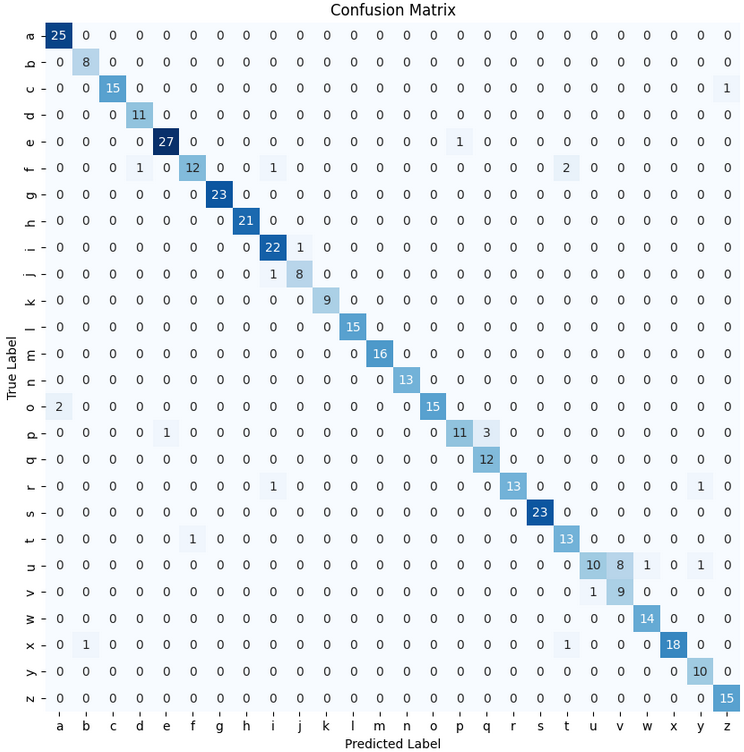
It can already be seen that very good results are achieved. Nevertheless, some confusion between letters can also be observed, such as in the case of "u" and "v", or in the case of "a" and "o". These are letters that can be confusing even for humans. When observing the data from which the neural network chose one output over the other, it can be seen that for a letter such as "a" or "o" it has a much harder time deciding that with an "m".
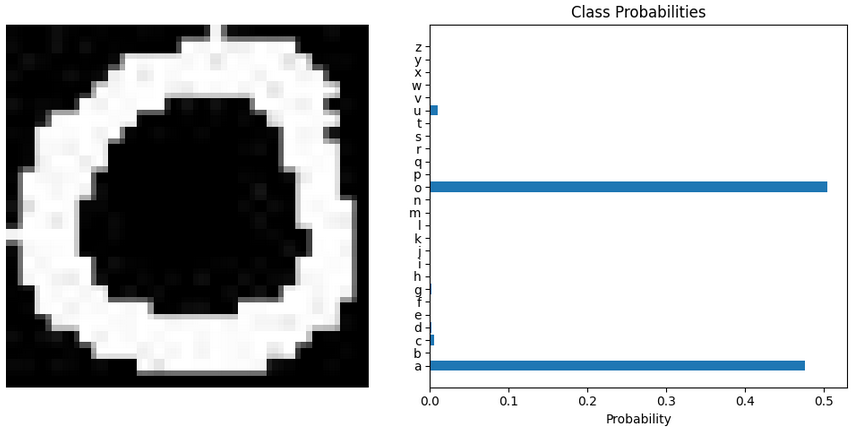
Ground truth="o"
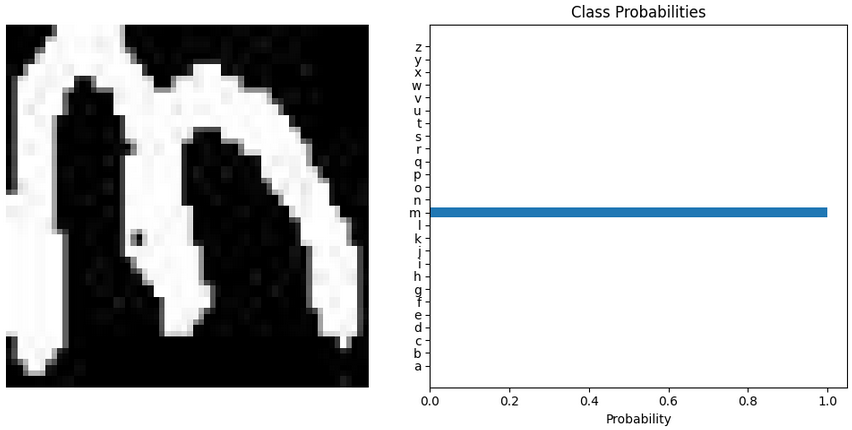
Ground truth="m"
UNET
Training the UNet was a bit more tricky, as we could not just have our classmates writing endlessly for us, whilst we spent the rest of our lives segmenting each character in order to train the encoder-decoder network.
Thus, with the dataset that had been generated, a code that could generate datasets was created. This code took as an input the entire text that our classmates wrote, and for each word generated different images, which contained the same word but written with different characters. For example, to write "the", the code would randomly select another "t", "h" and "e" to make the new word.
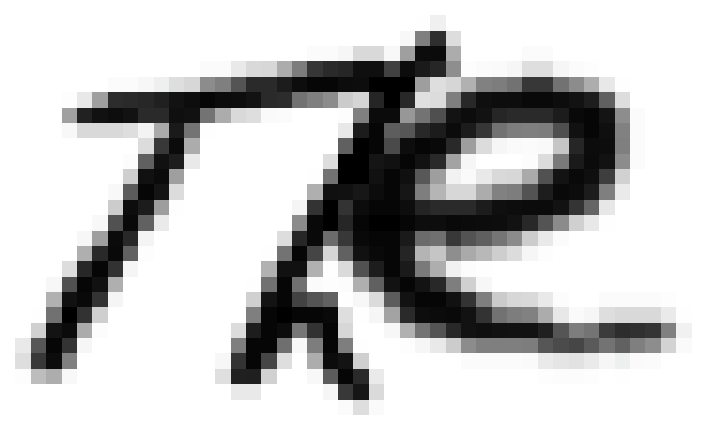
Auto-generated "the"
Auto-generated "brown"
Auto-generated "fox"
Generating the dataset like this helped with labelling the images. Since each letter was added individually, it was known what pixels belonged to that letter, thus the class label for each pixel was easily obtainable.
The training was performed like in the previous section, separating the dataset into training and validation. Since the prediction of UNet consists of an image full of labels, in order to obtain a proper confusion matrix, the validation dataset had to be changed to be a single character. This character was surrounded by a zero-padding in order to obtain the dimension the neural network was trained with.
After running the UNet with this new validation dataset, a softmax function was applied to obtain the likeliest character contained in the image, from which this confusion matrix was obtained:
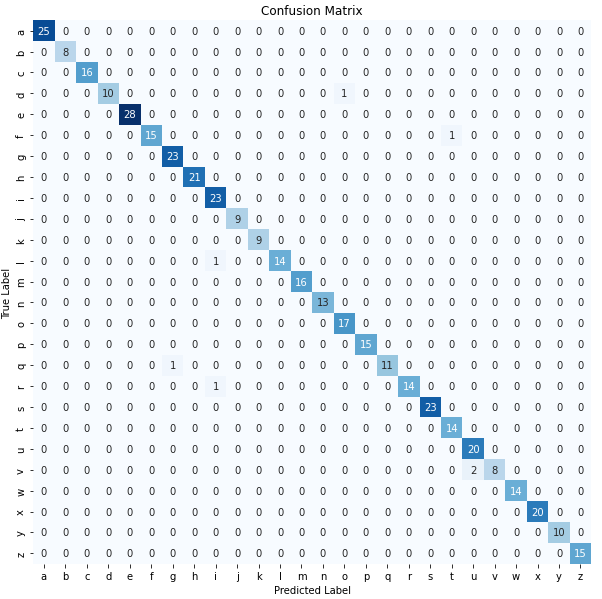
This all indicated that with the UNet we obtained better results than with the CNN. Even checking the original validation set made it seem like this model would work amazingly:

However, as new data was manually added (new handwritten words were added to the validation dataset), accuracy dropped incredibly fast:

Conclusions
UNets are hard to work with, and a lot of care must be put into the training process in order not to overfit.
CNN, on the other hand, have become such a known technology (to me) that it is easier to obtain good results with them.
PS: In the Github page, the same procedure has been followed but with the EMNIST Kaggle dataset instead of real data.